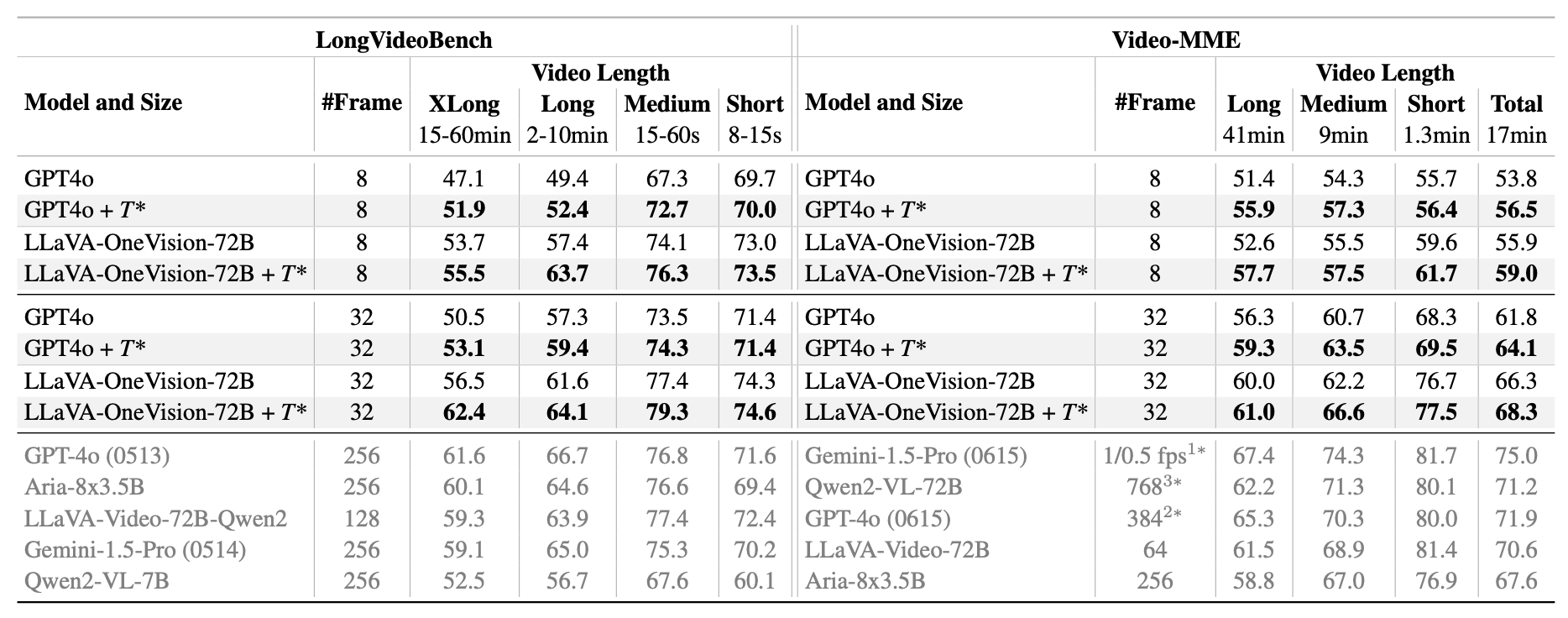
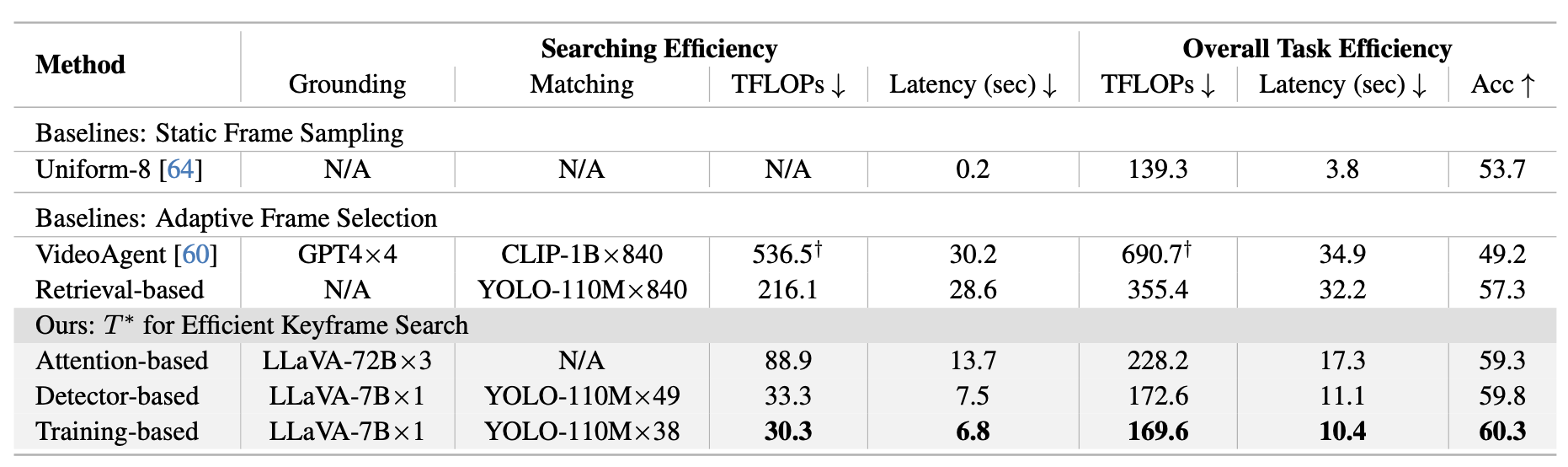
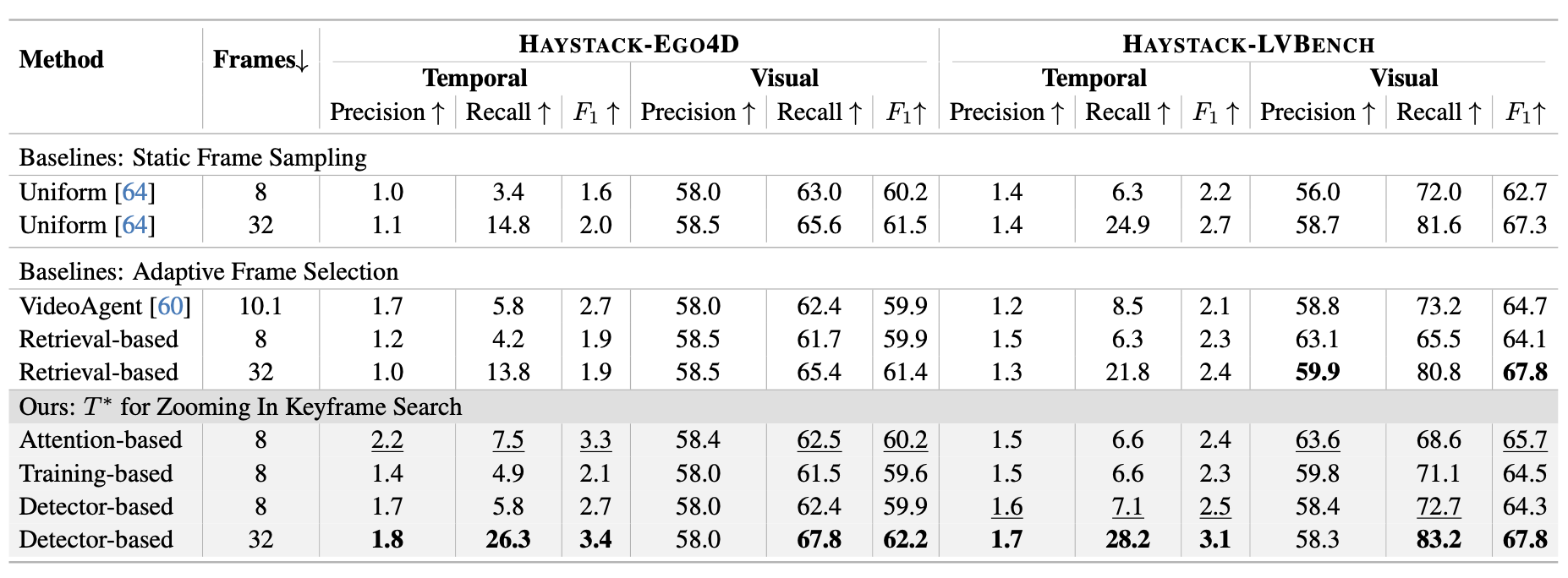
Method Overview
T* is an advanced temporal search framework designed to efficiently identify key frames relevant to specific queries. By transforming temporal search into spatial search, T* leverages lightweight object detectors and Visual Language Model (VLM) visual grounding techniques to streamline the process. T* demonstrates exceptional performance, both with and without additional training, making it a versatile and powerful tool for various applications.
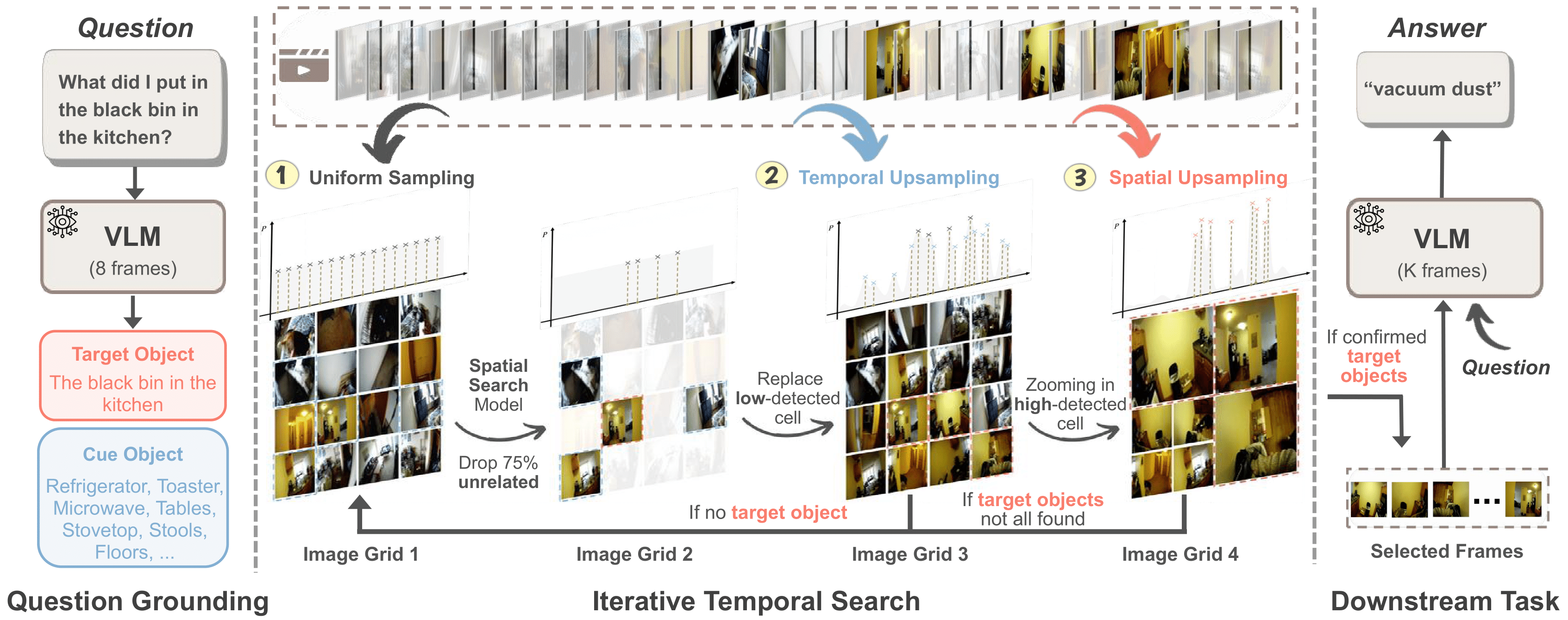
Figure 1. T* employs an iterative temporal search approach to search keyframes essential to answer questions.
Left: Question Grounding, where a visual language model identifies visual cues (target and cue object) from the textual question.
Center: Iterative Temporal Search, formulated as Spatial Search where a spatial search model iteratively detects visual cues and upsamples relevant temporal/visual regions.
Right: Downstream Task, where the visual language model answers questions using K keyframes sampled from the final temporal search distribution as visual input.

Figure 2. The algorithmic workflow of T* showing the iterative refinement process for keyframe selection.